
Kaicheng (Kevin) Guo
CS & Applied Math @ Brown | Reinforcement Learning, Continual Learning, Partial Observability
I am a fourth year undergraduate student concentrated in Computer Science and Applied Mathematics at Brown University. I currently conduct research in the Intelligent Robot Lab (IRL)advised by Prof. George Konidaris. My current research interest lies in continual learning and reinforcement learning in partially observable environments. Outside of research, I enjoy everything about science-fiction—favorites include Interstellar, Westworld, and The Three-Body Problem.
Education
Brown University
B.S. in Computer Science & Applied Mathematics (Honors)
- Overall GPA: 3.92/4.00
- Selected courses: Robust Algorithms for ML, Deep Learning, Computer Vision, Optimization, Learning & Sequential Decision Making, Systems for ML, Probabilistic Methods in CS, Functional Analysis, PDE, Honors Statistical Inference, Graph Theory, Abstract Algebra
Publications
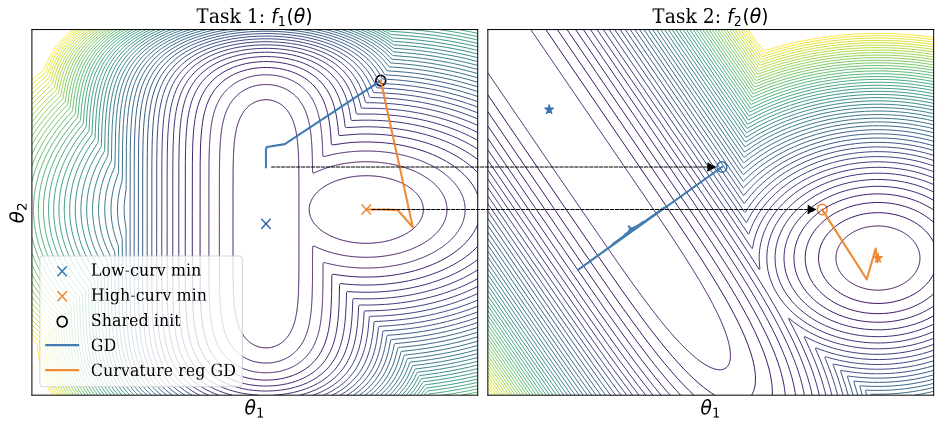
Spectral Collapse Drives Loss of Plasticity in Deep Continual Learning
Naicheng He*, Kaicheng Guo*, Arjun Prakash*, Saket Tiwari, Ruo Yu Tao, Tyrone Serapio, Amy Greenwald, George Konidaris
Under review at ICLR 2026; Accepted at NeurIPS ARLET Workshop 2025
We investigate why deep neural networks suffer from loss of plasticity in deep continual learning, failing to learn new tasks without reinitializing parameters. We show that this failure is preceded by Hessian spectral collapse at new-task initialization, where meaningful curvature directions vanish and gradient descent becomes ineffective. To characterize the necessary condition for successful training, we introduce the notion of τ-trainability and show that current plasticity preserving algorithms can be unified under this framework. Targeting spectral collapse directly, we then discuss the Kronecker factored approximation of the Hessian, which motivates two regularization enhancements: maintaining high effective feature rank and applying L2 penalties. Experiments on continual supervised and reinforcement learning tasks confirm that combining these two regularizers effectively preserves plasticity.
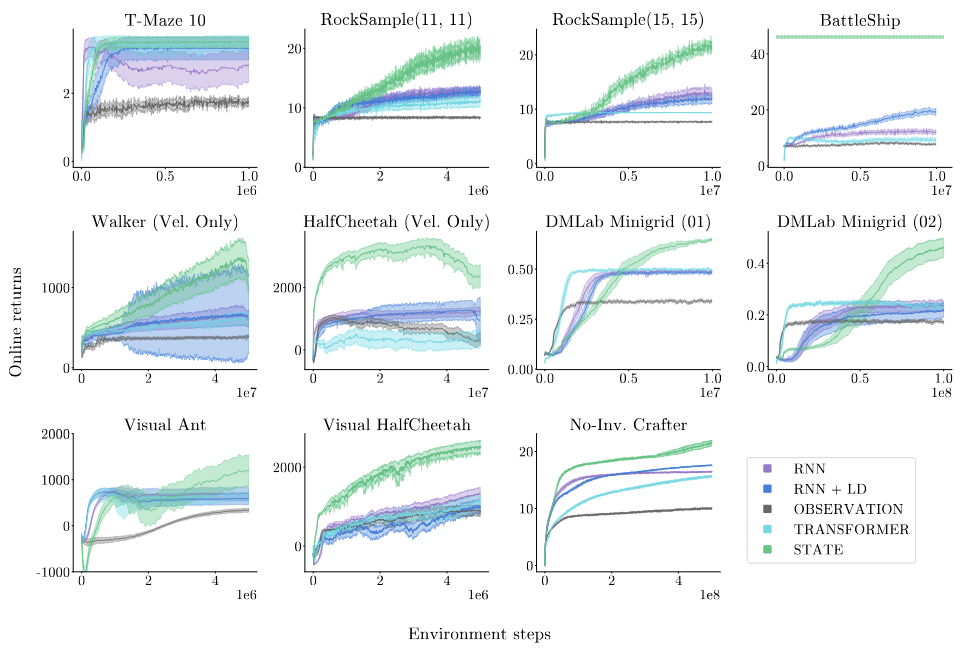
Benchmarking Partial Observability in Reinforcement Learning with a Suite of Memory-Improvable Domains
Ruo Yu Tao*, Kaicheng Guo*, Cameron Allen, George Konidaris
Reinforcement Learning Conference (RLC 2025)
Mitigating partial observability is a necessary but challenging task for general reinforcement learning algorithms. To improve an algorithm's ability to mitigate partial observability, researchers need comprehensive benchmarks to gauge progress. Most algorithms tackling partial observability are only evaluated on benchmarks with simple forms of state aliasing, such as feature masking and Gaussian noise. Such benchmarks do not represent the many forms of partial observability seen in real domains, like visual occlusion or unknown opponent intent. We argue that a partially observable benchmark should have two key properties. The first is coverage in its forms of partial observability, to ensure an algorithm's generalizability. The second is a large gap between the performance of agents with more or less state information, all other factors roughly equal. This gap implies that an environment is memory improvable: where performance gains in a domain are from an algorithm's ability to cope with partial observability as opposed to other factors. We introduce best-practice guidelines for empirically benchmarking reinforcement learning under partial observability, as well as the open-source library POBAX: Partially Observable Benchmarks in JAX.
Research
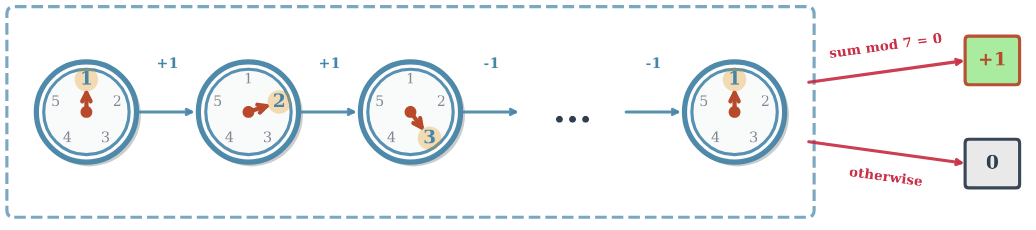
Exploration in POMDPs (In Progress)
Brown University
- Investigating trajectory-based exploration strategies for partially observable domains where traditional state-based exploration fails.
- Developed the Lock environment, where rewards depend on modular properties of full trajectories rather than single observations.
- Studying how memory traces and recurrent mechanisms enable agents to infer hidden structures and recover near-optimal memory function.
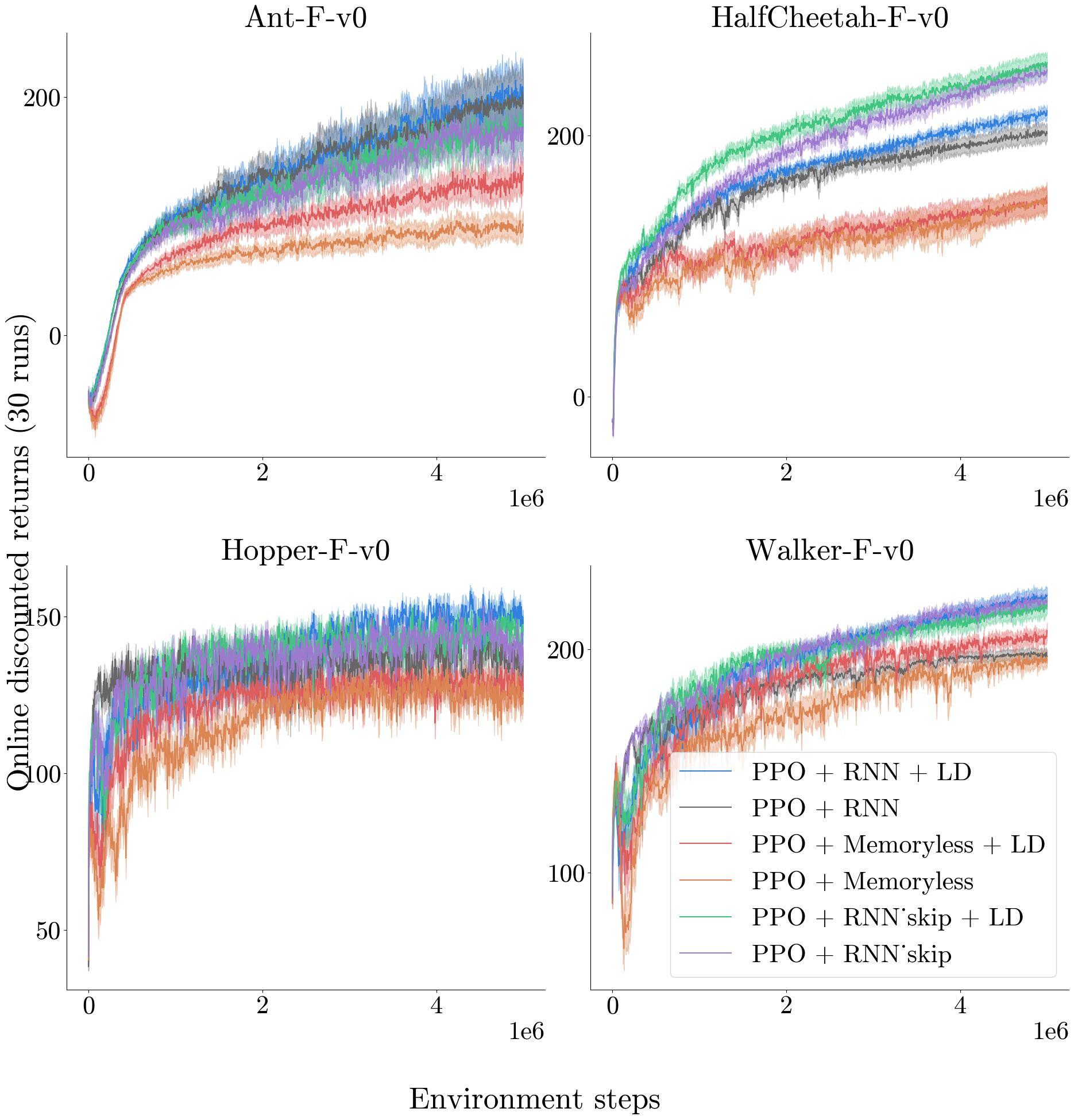
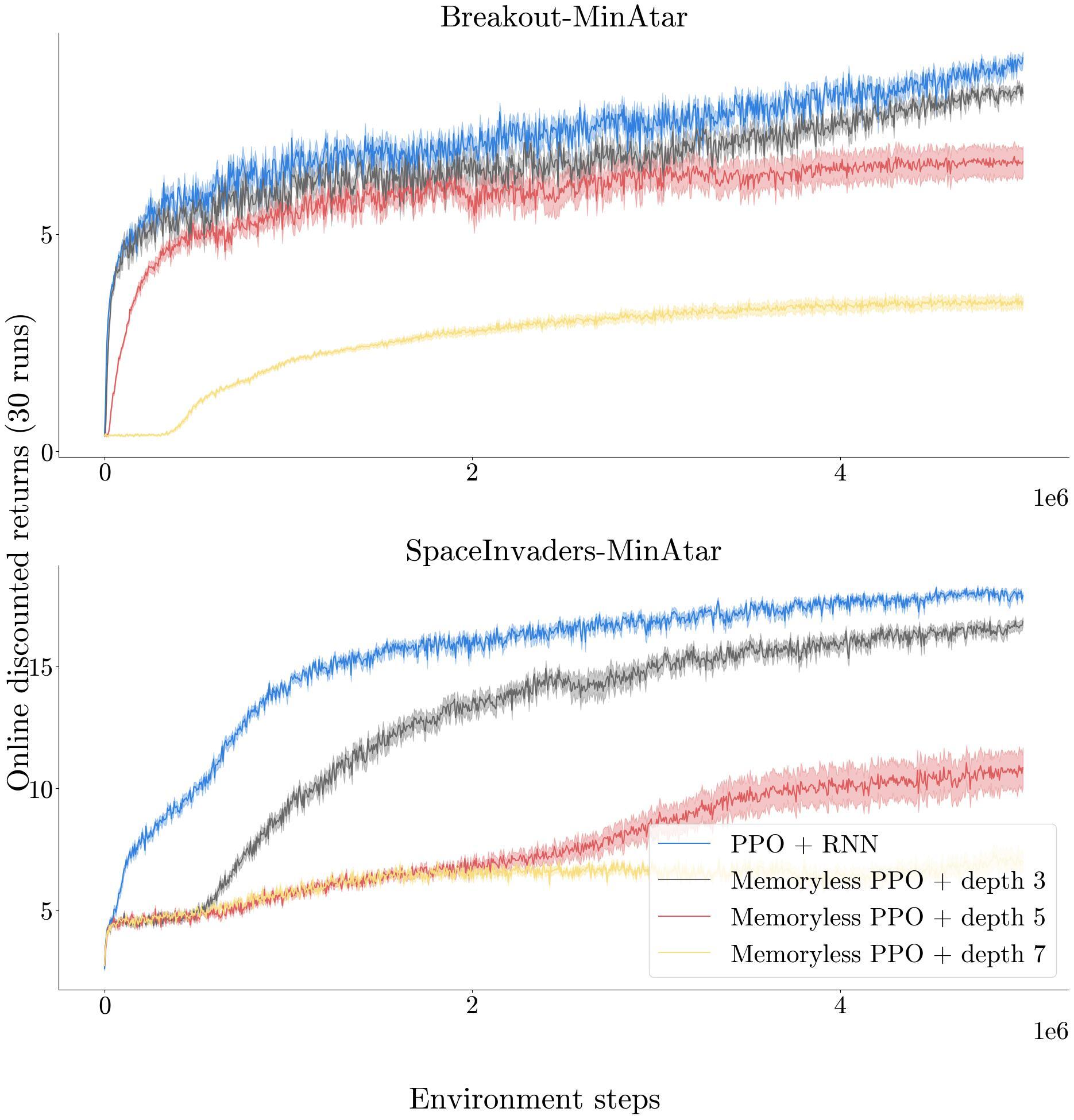
RNNs as Superior Function Approximators (In Progress)
Brown University
- Investigating why RNNs outperform MLPs even in fully observable environments.
- Demonstrated that MLPs break the Markov property after embedding and show empirically RNN exhibit greater expressiveness.
- Proposed RNN-Skip, a novel architecture that removes explicit recurrence while retaining the representational benefits of recurrent models.
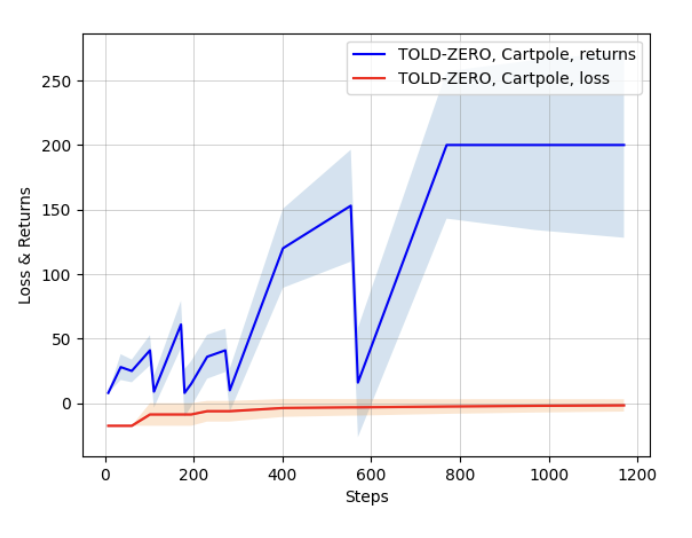
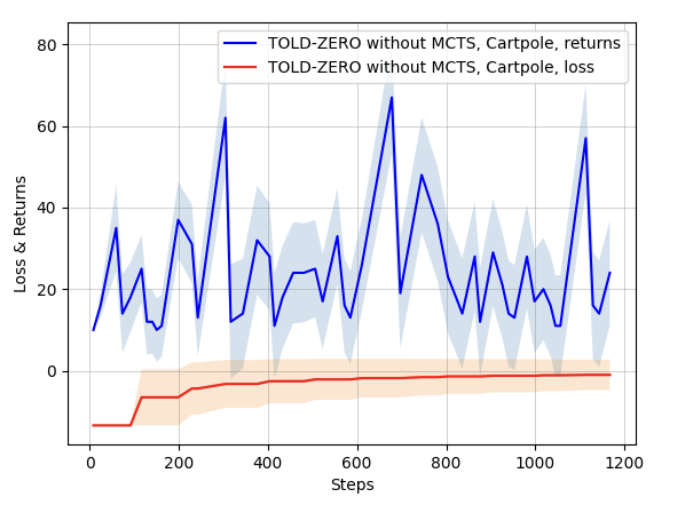
TOLD-ZERO: Model-Based Reinforcement Learning
Brown University
- Developed TOLD-ZERO agent for model-based reinforcement learning with improved sample efficiency.
- Implemented and evaluated performance on Cartpole environment, achieving stable returns of 200.
- Analyzed training dynamics showing high variability in early phases followed by stable convergence.
A Survey and Implementation of Fast Approximate Maxflow Algorithms
Brown University
- Conducted comprehensive survey of fast approximate maximum flow algorithms including theoretical analysis and practical implementations.
- Implemented and compared performance of various maxflow algorithms across different graph types and problem sizes.
- Analyzed trade-offs between accuracy and computational efficiency in approximate solutions to network flow problems.
Experience

Research Intern: RL for Manipulation in Unknown Environments
Robotics Institute, Carnegie Mellon University
PI: Maxim Likhachev
- Designed a manipulation framework under complete visual occlusion using tactile + proprioception only.
- Enabled actions on target objects without visual input for robust real‑world systems.
Undergraduate Teaching Assistant
CS2951F: Learning and Sequential Decision Making (Graduate)
Brown University
Lecturer: Michael Littman